

NURBS ray tracing
Curves
3/17/2024
The general form of NURBS is defined as:
, where N is the B-Spline basis function, n is the number of control points, are the weights, are control points, and k is the degree.
The B-Spline basis function of degree 0 is defined as:
For higher degrees, the B-Spline basis functions are defined recursively:
, where are knots, is the degree.
Surely, calculating this function when rendering every frame is horribly slow, but luckily, we're able to simplify this if we know what degree we want.
Interpolation in Graphics World
Part 3 Cubic Convolution
2/27/2023
Cubic convolution provides a fast way to interpolate the texture data, which Keys originally proposed. With this method, texture sampling can be simplified to taking four samples, multiplying them with four weights, and adding all of them together. It takes discrete image data and an interpolation kernel and outputs continuous data. The convolution kernel is the following:
Where is a constant, we usually choose as the value. To apply the above kernel, we use the following function:
Where is the index of the input image data, is the colour value, and is the interpolation point. Because is if is not in the range of , can only be the four nearest indexes to .
For example, if is 5.5, then can only be , , and , and the parameter of the kernel function can only be , , and . We then take the four pixels and multiply them by , resulting in:
Interpolation in Graphics World
Part 2 Splines
2/22/2023
In the last article, we discussed polynomial interpolation. It works, but we will struggle to find coefficients for big data sets. Instead of using polynomial interpolation, we can use splines to solve this issue.
Splines define multiple pieces of a curve and keep the curve smooth by ensuring the tangent of each point on the curve is continuous. Therefore, it does not need to increase the degree when we add more values to interpolate. This article is going to discuss some commonly used splines.
B-Spline Curves
The form of the B-Spline is defined recursively.
Where is the degree of the spline; is knots; is control points; is the B-spline basis function, defined by:
Interpolation in Graphics World
Part 1 Polynomial Interpolation
2/16/2023
Interpolation is commonly used in computer programs. The most common interpolation method is linear interpolation, which takes two values and generates continuous uniform distributed results. For example, say we have a data set [10, 30, 40, 0]. The linear interpolation result of the data set will be like the following:
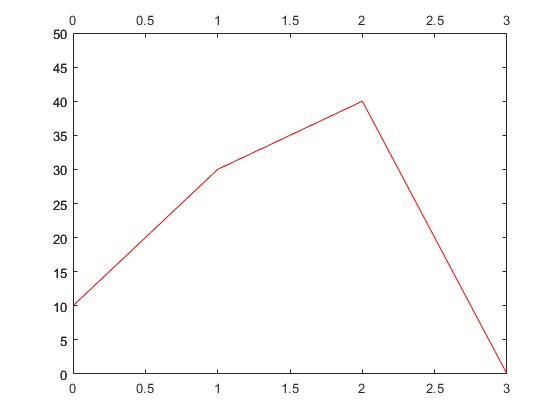
As the figure shows, linear interpolation does generate a continuous result. However, the curve that it generates could be smoother. Sometimes, we may not want those sharp corners. For example, if we're going to describe a spherical object, those sharp corners may make it look bad; Or if we are trying to interpolate an image, we may find the interpolated image weird.
To address this issue, we should use interpolation methods which generate smooth results.
Polynomial Interpolation
The data set [10, 30, 40, 0] contains four values, which means to describe a curve passing all four points, we need a three-degree polynomial, . Where , , and are coefficients, we will need to find them out. It is easy because with known and values, we can create a linear system based on them and use matrices to solve the issue.
The linear system based on the data set is:
And the matrix form of the above is:
Multisample Anti-aliasing
2/15/2023
The Image Distoration Issue and Anti-aliasing Algorithms
In 3D rendering, aliasing or image distortion is a difficult part that requires a lot of calculations to solve. It distorts images and makes images a bit ugly. For example, the following image was rendered by my SWRenderer project without any anti-aliasing:

The edges of the box are jagged.
![]()
Luckily, there are a few ways to tackle this issue. The simplest way is supersampling. It is to divide each pixel into multiple subpixels, render each subpixel and output the average value of the subpixels for each pixel. However, despite this method being able to solve the issue perfectly, it needs too much calculation and is almost impossible to use in realtime rendering. Instead, multisample is more commonly used.
The multisample algorithm only renders each pixel once, but it still gives an excellent result.
The Algorithm
![]()
Say we are rendering a triangle like the above. The blue points are the subsamples, and the red triangle is the triangle we are rendering.
Without multisampling, the output image may look like the following, as only pixel 5 is fully covered by the triangle.
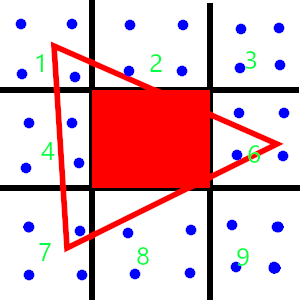
To make the image better, we divide pixels which are not fully covered by a triangle into a couple of subpixels. Instead of rendering them, we only use them to calculate the coverage of the pixel. If a pixel is fully covered, we deem the coverage of the pixel to be 100%.
Code management issues in big projects
2/11/2023
In my experience, code refactoring has been an anguish in big projects. It may be repetitive and tedious and take a long time to finish. But the result might also be disappointing, as it does not directly create value, and the refactoring may cause some issues. But, with projects getting bigger and bigger, refactoring is always needed.
In this article, I will discuss the code mangement issues in big projects. I will also introduce a few tools and concepts regarding code management.
Code analysation
I have worked on a project with more than 300,000 lines of C++ code that had some code management issues. For example, some old code in the project still used the singleton pattern. However, we have replaced the old singleton pattern with a new factory, and the factory should create all the service classes to make the code easier to split and reuse. One day, the project leader suddenly decided to refactor the code base. Since the code base was too huge, four people were working on the refactoring at the same time. But the refactoring still took weeks to finish. The project had some code like this:
std::string filePath = ProjectService::GetInstance().DownloadProjectFile(projectID);
ViewerService::GetInstance().OpenFile(filePath);
If the code base is small, it is unnecessary to refactor this piece of code. However, when the code base has grown to 300,000 lines with hundreds of services, it makes sense to split some services into their library files. However, with the singleton pattern, it's impossible to separate the code as the GetInstance method is one of the member functions of a service and must exist in the main executable file.
Now, here is a question. How are we supposed to refactor code like this if we have tons of code?
In my opinion, repetitive and boring jobs should always be handled by machines to ensure humans can make no mistakes. Clang may be used in this case to solve similar issues.
Clang is not just a compiler but also a library providing APIs for generating ASTs. ASTs offer a way to interact with the code with meaningful details. For example, the above code may be translated into a tree like the following:
| `-CompoundStmt 0x11902e0 <line:20:1, line:24:1>
| |-DeclStmt 0x1190158 <line:21:5, col:88>
| | `-VarDecl 0x118fef0 <col:5, col:87> col:17 used filePath 'std::string':'std::__cxx11::basic_string<char>' cinit destroyed
| | `-ExprWithCleanups 0x1190140 <col:28, col:87> 'std::string':'std::__cxx11::basic_string<char>'
Creating a Dependency Injection Library in C++
Part 2 Parameters Counter
8/28/2018
The previous article has solved the difficulty of retrieving the types of services that a type being injected needs. This article discusses how to get the number of services (parameters) that a type being injected needs.
Constructors in C++ can have both required and optional parameters and multiple overload constructors. Because of this, it is impossible to get the number of parameters that a constructor needs accurately.
To inaccurately get the parameters a constructor needs, developers may ask the compiler if a type can be constructed with a specific list of arguments. If the constructor accepts a list of arguments, then the length of the list is the number of parameters the constructor needs. However, this only works if a constructor has optional parameters or multiple overload constructors.
std::is_constructible can be used to check if a specific list of arguments can construct a type.
std::is_constructible<T, Args...>
struct A
{
A(int, int) {}
}
// yes
static_assert(std::is_constructible<A, PlaceHolder, PlaceHolder>::value, "constructible");
std::integer_sequence / std::index_sequence
Then, with the type mentioned in the first article, PlaceHolder and std::integer_sequence and recursive template functions, it is possible to use std::is_constructible to get the number of parameters a constructor needs.
Creating a Dependency Injection Library in C++
Part 3 Service Binding
8/28/2018
The previous article discusses how to determine the number of parameters a function accepts. This article discusses the implementation of dependency injection.
Bindings may be used to describe the types of service interfaces and the types of implementations of services. Developers may use a template to create a Binding class.
Implementation of a Binding
A simplest implementation of a Binding may look like the following:
template <typename T>
struct Binding
{
using typename Type = T;
std::function<T()> provider;
};
Binding<int> myBinding{[]{ return 10; }};
In the above example, the type alias Type is the type of a service interface; the provider is a provider that creates an implementation of the service type; the myBinding is a provider that returns an integer with a value of 10.
Bindings should be stored in the PlaceHolder type mentioned in the previous articles, which makes the PlaceHolder type an actual injector. Inside the injector, a container may store all the Bindings a program has. This article uses std::tuple as the container.
auto bindings = std::make_tuple(Binding<int>([]{ return 10; }), Binding<float>([] { return 2.1f; }));
Asynchronous Socket with C++ Coroutine TS
Part 3 Win32 IOCP API
8/26/2018
Almost every IO-related API in Windows allows an Overlapped parameter, allowing developers to call the APIs asynchronously.
Before discussing the IOCP APIs, it is necessary to introduce APIs for creating and interacting with thread pools. Those functions help developers to use the callback mechanism of IOCP APIs.
An ordinary practice of using IOCP for asynchronous IO is as follows:
- Start an IO thread pool, and bind it to a socket;
- Start an asynchronous IO operation;
- When the operation is done, windows will call the callback function on the IO thread pool.
The CreateThreadpoolIo API is used to start an IO thread pool.
CreateThreadpoolIo
PTP_IO CreateThreadpoolIo(
HANDLE fl,
PTP_WIN32_IO_CALLBACK pfnio,
PVOID pv,
PTP_CALLBACK_ENVIRON pcbe
);
Creating a Dependency Injection Library in C++
Part 1 Parameter Placeholders
8/26/2018
In other programming languages, developers use the reflection mechanism to implement dependency injection libraries. However, the static reflection features have not been added to C++ yet. However, it does not mean there are no ways to achieve it in C++. This article is to discuss a new method being able to achieve dependency injection in C++.
The most challenging part of doing dependency injection is getting the type of services needed by the class being injected. There are no ways to do this in C++. However, developers may use template meta-programming and implicitly type conversion to achieve it.
Imagine type PlaceHolder can be converted to any other type, and type A accepts four different types of parameters to construct itself, then four objects of A can be used to create an instance of type B.
E.g.
struct A
{
A(int, bool, double, int)
{
}
};
// The normal way to create an object of `A`
A a(1, true, 1.2, 3);
struct PlaceHolder
{
// The type `PlaceHolder` now supprts to be converted to any types
Asynchronous Socket with C++ Coroutine TS
Part 2 Implement your Coroutine.
8/19/2018
Promise and Future
Before we dive into the coroutine itself, we should get familiar with the Promise and the Future. Compared with callbacks, the Promise provides a consistent way to return a result or an error in a non-blocking function, and the Future provides a consistent way to retrieve them.
future<int> do_something_async(int a)
{
std::shared_promise<int> p;
// A non-blocking function using callback functions
// This function is from a library, and the first parameter of the callback function is the result
// and the second one is the errorCode
nonblocking_fetch_data_from_db([p, a](int result, int errorCode)
{
// This function is from another library, and the first parameter of the callback function is an
// errorCode but with a different type, and the second parameter is the file data
nonblocking_read_file([p](error_code errorCode, const std::string& fileData)
{
p.set_result(std::stoi(fileData));
});
});
return p.get_future();
Asynchronous Socket with C++ Coroutine TS
Part 1 Coroutines in C++
8/17/2018
The coroutine
Finally, the coroutine feature is set to add to C++. But wait, what does the coroutine do, and why should we use it? The coroutine feature solves the Callback hell issue, which most front-end developers probably have experienced. It basically makes the asynchronous code looks like synchronised code but without blocking the executing thread.
The following code is from a socket server, which uses callback functions to handle new connections with a very basic handshake validation. It basically shows how the Callback hell destroys developers' minds.
void s1_callback(error_code ec);
void c1_callback(error_code ec);
void s2_callback(error_code ec);
void c2_callback(error_code ec);
void handle_connection()
{
auto s1_buffer = std::shared_ptr<BYTE[]>(new BYTE[HANDSHAKE_S1_SIZE]);
auto self = shared_from_this();
read_async(socket, s1_buffer.get(), s1_buffer.size(), [=](){
self->s1_callback();
});
}
void s1_callback(error_code ec)
Making an IOC container in Python
Part 3 The Service Container
10/11/2017
Service Container
A service container may be used to store all the services the program needs and provide a way to register each service and how to create them. This article shows a simplest service container and a simplest injector look like.
A simplest service container may look like the following:
class ServiceContainer(IServiceContainer):
def __init__(self):
self._type_container = []
def register_service(self, service: Type):
self._type_container.append(service)
def create_service(self, t: Type):
Service = next(ServiceType for ServiceType in self._type_container if ServiceType == t)
return Service()
The above code uses a list to store all the services, and when the create_service method gets called, it takes the service from the list and creates the service.
Injector
As we mentioned before, an injector may be used to resolve the dependency a class needs and create an instance of the class.
Making an IOC container in Python
Part 4 Service Providers
10/11/2017
With the simplest service container we created in the previous article, now we can look at making the service container provide a way to customise service creation. To achieve this, service providers may be used.
Imagine how a MySqlDBConnection service would look like:
class MySqlConnection:
def __init__(self, host, port, database):
...
We do not want the MySqlConnection service to read the configuration by itself, as this part of code is not relating to what this service should provide.
Typically, we will need to read the host address, the port number, and the database from a configration file to instantiate the above service. We may introduce a service provider class to achieve this.
Service Provider
A provider class for the MySqlDBConnection service should be:
class MySqlConnectionProvider(IServiceProvider):
def __init__(self, configuration: IConfiguration):
self._configuration = configuration
def provide(self):
return MySqlConnection(
self._configuration["db_host"],
self._configuration["db_port"],
Type Hinting in Python
7/22/2017
In Python, the types of variables may change during the execution of the program. It makes the code more flexable but it also confuses developers and the IDE sometimes, as both of them may need to analyse the code to find out the types of variables.
To solve this issue, Python introduced the Type Hinting feature. It allows developers declare the types of variables like what developers do in static-typed languages. For example:
def add(a: int, b: int):
return a + b
When calling the above function with some other types of parameters, IDE will be able to tell the developers it is not what the function expects. For example:
sum('a', 'bcd') # Developers will be warned
It also helps IDEs to provide suggestions. For example:
l = ['a', 'b', 'c', 'd']
def foo(arr):
for i in arr:
i. # type of i is unknown, the IDE is not able to provide any suggestions
# VS
Making an IOC container in Python
Part 2 Resolving Dependency
7/22/2017
The most essential part for resolving the dependency is retrieving the dependency declared by the __init__. To achieve this, we may use the inspect module. This article will share how I managed to do this with this module in my past projects.
The inspection module's documentation can be found on this page.
Retrieving the types of parameters
We may use the signature function to retrieve parameters and their types.
def test(a: int):
...
inspect.signature(test) # <Signature (a: int)>
parameters = signature.parameters # mappingproxy(OrderedDict([('a', <Parameter "a: int">)]))
The signature function returns a Signature object, from which we can access the parameter declaraction including the type hinting of each parameter by accessing it's parameters property.
How we may do it looks like the following
class Test:
def __init__(self, a: IConfiguration):
Making an IOC container in Python
Part 1 Dependency Injection
7/21/2017
Class decoupling
Imagine there is a class UserRepository which reads configuration using ConfigurationManager, processes user-related actions, and stores user data in the database using MySqlConnection.
class UserRepository:
sqlConnection: MySqlConnection
configurationManager: ConfigurationManager
def __init__(self):
self.sqlConnection = MySqlConnection("localhost", 3306, "username", "password", "utf8")
self.configurationManager = ConfigurationManager("/app.xml")
# ...
This class depends on ConfigurationManager and MySqlConnection, which implement services instead of interfaces. Therefore, if we were to switch the database from Mysql to SqlServer, it would cost developers a lot of effort to change the dependency. Also, a class should only care about how its implementation instead of the implementation of other services.
To decouple the above classes, we should make an ISqlConnection interface for MySqlConnection and an IConfigurationManager interface for ConfigurationManager and let both types inherit from the interfaces. Then, we can refactor UserRepository to the following:
class UserRepository:
sqlConnection: ISqlConnection
configurationManager: IConfigurationManager
def __init__(self):
self.sqlConnection = ServiceFactory.createService(ISqlConnection)
self.configurationManager = ServiceFactory.createService(IConfigurationManager)
ES7、ES8最新特性
7/17/2017
Array.prototype.includes
以后,如果只想知道元素是否在数组当中,可以使用arr.includes(...)来取代旧的arr.indexOf(...) !== -1,
类似于Python中的in操作符.
Array.prototype.indexOf 返回元素在数组中的位置,若不存在,则返回-1。
相比而言,Array.prototype.includes 返回boolean类型,true表示该数组包含此元素,否则为false。
在以前,必须使用这样的语法:
let arr = [1, 3, 5, 7, 9];
if (arr.indexOf(3) !== -1)
{
// includes
}
// or
if (~arr.indexOf(3)) // where `~` is equivalents -(x + 1)
{
// includes
}